
Hi! I am Xuan Gong (Chinese name: 龚宣; I also go by Xander), a first-year Ph.D candidate at Shanghai Jiao Tong University.
My research interests mainly focus on VLM and LLM, especially about reasoning and agent.
If you are interested in partnering on research projects, offering internship opportunities or exchange programs, I would be thrilled to connect with you.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Shanghai Jiao Tong UniversitySchool of Computer Science
Shanghai Jiao Tong UniversitySchool of Computer Science
Ph.D. CandidateSep. 2025 - present -
 Tongji UniversityB.S. in Computer Science (GPA rank top 5%)Sep. 2021 - Jul. 2025
Tongji UniversityB.S. in Computer Science (GPA rank top 5%)Sep. 2021 - Jul. 2025
Honors & Awards
-
National Scholarship of China2022
-
Outstanding Graduate of Tongji University2025
-
First Prize of The 14th National University Student Mathematics Competition Non-Mathematics Category (Shanghai Region)2022
-
2023 CCF-BDCI competition, 8th place (1st of undergraduate teams) in B list of the track "Deployment of super resolution model based on tpu platform"2023
News
Selected Publications (view all )
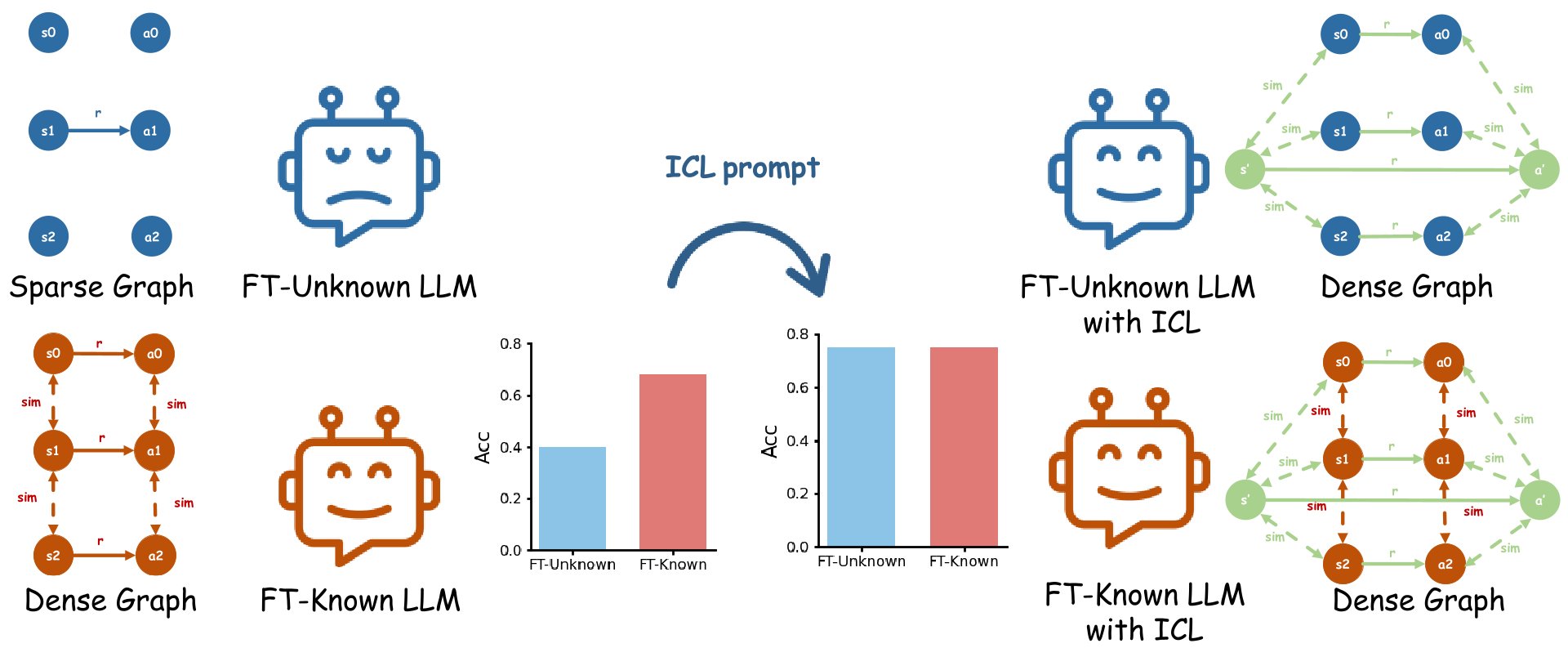
From Parameters to Prompts: Understanding and Mitigating the Factuality Gap between Fine-Tuned LLMs
Xuan Gong, Hanbo Huang, Shiyu Liang# (# corresponding author)
PreprintUnder review. 2025
We revisit how supervised fine-tuning affects factual knowledge in LLMs, revealing a factuality gap between known and unknown knowledge. This gap can be mitigated at inference via in-context learning (ICL) or out-of-distribution prompts. Our theoretical and empirical results show that test-time prompts can overshadow fine-tuning data, suggesting ICL can compensate for poor fine-tuning and should be considered in evaluating fine-tuning strategies.
From Parameters to Prompts: Understanding and Mitigating the Factuality Gap between Fine-Tuned LLMs
Xuan Gong, Hanbo Huang, Shiyu Liang# (# corresponding author)
PreprintUnder review. 2025
We revisit how supervised fine-tuning affects factual knowledge in LLMs, revealing a factuality gap between known and unknown knowledge. This gap can be mitigated at inference via in-context learning (ICL) or out-of-distribution prompts. Our theoretical and empirical results show that test-time prompts can overshadow fine-tuning data, suggesting ICL can compensate for poor fine-tuning and should be considered in evaluating fine-tuning strategies.
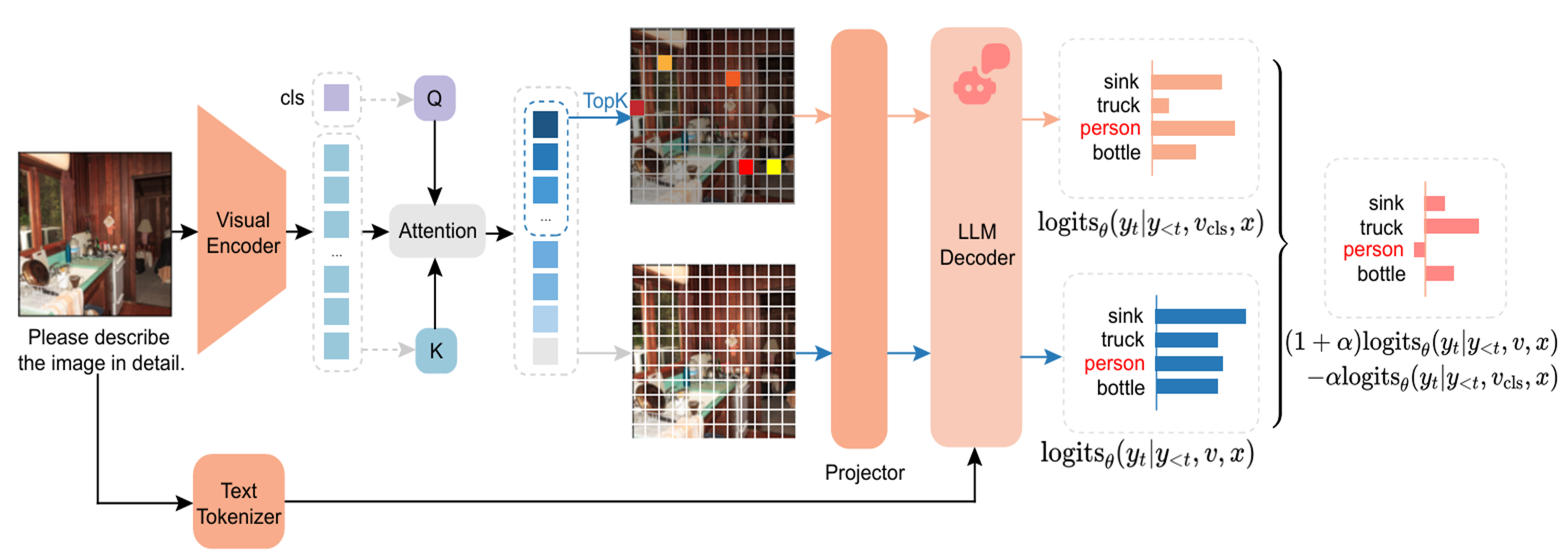
DAMRO: Dive into the Attention Mechanism of LVLM to Reduce Object Hallucination
Xuan Gong, Tianshi Ming, Xinpeng Wang, Zhihua Wei# (# corresponding author)
EMNLP 2024 Main
We propose DAMRO, a training-free method to reduce object hallucination in LVLMs by filtering misleading high-attention background tokens using the ViT CLS token. DAMRO significantly improves hallucination control on models like LLaVA and InstructBLIP across multiple benchmarks.
DAMRO: Dive into the Attention Mechanism of LVLM to Reduce Object Hallucination
Xuan Gong, Tianshi Ming, Xinpeng Wang, Zhihua Wei# (# corresponding author)
EMNLP 2024 Main
We propose DAMRO, a training-free method to reduce object hallucination in LVLMs by filtering misleading high-attention background tokens using the ViT CLS token. DAMRO significantly improves hallucination control on models like LLaVA and InstructBLIP across multiple benchmarks.